

The Production Context Stack
The third layer most studios haven’t built yet.

AI adoption in games is at 36%. Durable results are at 5%. The gap is structural.
A production now has deliverables, process, and a Production Context Stack
The Production Context Stack is version-controlled, agent-readable, and maintained like any other critical project asset
Here’s what it consists of and how to start building one

The GDC 2026 State of the Game Industry survey found that 36% of game industry professionals already use generative AI in their daily work. A separate Q3 2025 report on AI in gaming found that only 5% of pilot AI projects actually reach production and generate real benefits.
That gap, between widespread adoption and durable results, is not a model problem. The models are good enough. The gap is structural.
I’ve watched this pattern up close. Producers who’ve adopted AI have generally done the same thing: they’ve added it to how they already work. They reach for Claude when they need a first draft, use Copilot when they need code, paste a spec into ChatGPT for a second opinion. This produces results. It is not infrastructure.
The difference between a tool and an agent is context. A tool does what you ask. An agent does what you mean, but only if it understands your project, your naming conventions, your definition of done, your team structure, your art pipeline review stages. And here’s the problem: every session starts from zero. The agent knows nothing. You brief it again. You explain the ticket hierarchy. You describe the LiveOps calendar. You clarify what “approved” means in your pipeline. Every time.
That briefing cost is invisible until you add it up. Every session you spend re-deriving state that should already exist is a session you didn’t spend building. The producers getting compound returns from AI aren’t better at prompting. They’ve built the layer that makes re-briefing unnecessary.
That layer has a name. Most people building it haven’t given it one yet, which is part of why it keeps getting built in fragments rather than as a system.
The three layers
Every game production has two layers that people can name without thinking. The first is deliverables: features, specs, assets, tickets, design documents: the actual output. The second is process: Kanban, ceremonies, reviews, handoffs, the system governing how deliverables get made and shipped.
The third layer is newer, and most studios don’t have it. Call it the Production Context Stack: the configuration and context you build around the model so an agent is productive in your specific production context.
The Production Context Stack is infrastructure. Version-controlled, agent-readable, maintained like any other critical project asset.
The distinction matters practically. Tools get bolted on. Infrastructure gets built in. A producer who opens Claude each morning and briefs it from scratch is using a tool. A producer whose agent loads the project constitution, inherits the domain rules, and picks up where yesterday’s session ended is working with infrastructure.
The gap between those two experiences compounds over time. The first producer gets faster answers to individual questions. The second gets a system that accumulates institutional knowledge, maintains consistent conventions, and applies domain expertise without being taught it again each session. The production itself becomes a training environment, not for the model, but for the configuration around it.
Most producers who’ve been building seriously with AI for more than six months have started forming the third layer without recognising it as a category. A prompts folder they version-control. A naming conventions doc they paste into every session. A shortlist of trusted instructions they’ve learned through trial and error and now treat as standing rules. These are proto-Production-Layer artefacts. They’re working. The gap is usually three things: the pieces aren’t connected, they’re not maintained on a deliberate schedule, and they’re not designed to be read by an agent rather than a human.
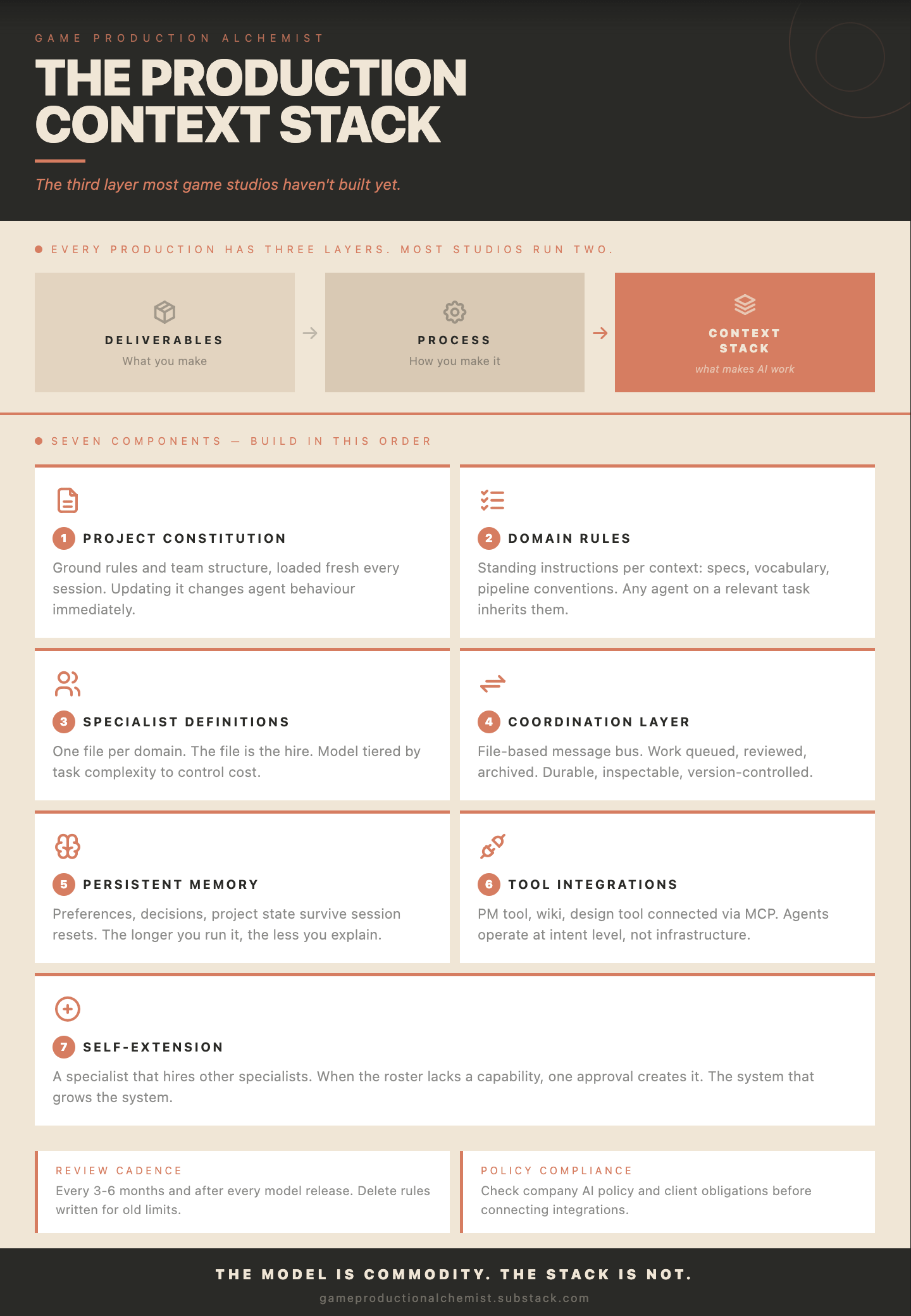
What the Production Context Stack consists of
The layer has seven components. They don’t need to be built simultaneously, but they have dependencies: the usefulness of each increases as the others exist.
1. Project Constitution
The durable, authoritative instruction file the agent reads at the start of every session. Ground rules, team structure, naming conventions, standard operating procedures, and the hard rules governing how the orchestrator behaves.
Three properties matter here. First, it’s version-controlled alongside your deliverables, not stored in a notes app or held in someone’s head. Second, it’s loaded fresh every session: updating it immediately changes agent behaviour across all future runs, no redeployment or restart required. Third, it defines the orchestrator constraint: the top-level agent routes and delegates, but never does substantive work directly. That single rule keeps the context window clean and the outputs auditable.
Think of it as the answer to one question: if an agent joined this production today with no briefing, what would it need to know to work correctly?
2. Domain Rules
Standing instructions for specific contexts: how you write specs, how the art pipeline review process works, what “done” means for a ticket at each stage, your LiveOps vocabulary, your localisation conventions. A domain rules file is a reference file any agent inherits automatically when working on a relevant task.
The practical difference between domain rules and a prompt is maintenance. A prompt lives in your head or in a notes doc. A domain rules file lives in version control, gets reviewed when the project changes, and accumulates institutional knowledge over time. When a new producer joins the team, domain rules files are their onboarding documentation. The work of writing them down pays dividends twice.
3. Specialist Definitions
Each domain gets its own agent file: identity, role, procedures, reference material, and rules. Creating the file creates the capability. Your roster extends by adding markdown files.
Model tiering matters here and saves real money at scale. Complex multi-file work warrants the most capable model. Standard design, engineering, and research tasks run on a mid-tier model. Administrative work (roster management, metadata updates, ticket triage) runs on a faster, cheaper model. A production generating hundreds of agent calls per day sees this difference in cost immediately.
The file is the hire. When you need a new specialist, you write their brief, and the capability exists.
When a task requires expertise the roster doesn’t cover, the system can research and create a new specialist file without requiring you to touch the core infrastructure. The roster is designed to grow with the production.
4. Coordination Layer
Multi-agent work needs a mechanism for passing work between specialists and back to you. The simplest version is a folder structure: deliverables queued for your review in one location, files moving between agents in another, completed items archived in a third.
A hook on session start checks for new files in the review queue and injects an alert into the agent’s context if anything is waiting. This creates an async notification system without polling, without a database, without a framework. Durable, inspectable, and version-controlled in git.
The coordination layer is where most producers who build multi-agent setups eventually spend their design attention, because it’s where the workflow bottlenecks surface most clearly. When the layer works, work flows. When it doesn’t, the agent does the right task in the wrong order and you don’t find out until too late.
5. Persistent Memory
Every agent starts a new session cold. Persistent memory is what gives it continuity without a database.
Each specialist has its own memory directory: preferences, prior decisions, project state, feedback corrections. A project-level index loads at session start, giving the orchestrator recall across conversations. Memory is typed (user preferences, project state, accumulated feedback, reference data) and stored as markdown files with metadata. When a session approaches the context window limit, the system compresses prior turns into a structured summary. The following session loads that summary and resumes.
A long workflow spanning multiple days progresses across sessions without the user re-briefing the system. That’s where the returns compound.
This is the component that most clearly separates working with an agent from working with a tool. A tool has no memory. An agent with persistent memory has accumulated context about your project, your preferences, and the decisions you’ve made. The longer you run it, the less you have to explain.
6. Tool Integrations
Your project management tool, wiki, and design tool are connected so agents can call them directly at the level of intent rather than infrastructure. An agent working in your PM tool operates on named actions (edit issue, create issue, search by query, transition status) rather than REST endpoints. No HTTP client code, no authentication handling, and no entire class of implementation error.
The scale consequence matters. Because each edit-issue call is independent, a specialist can fire dozens of API calls in a single pass. Reparenting fifty tickets, updating components, resetting fix versions: operations that would take a human project administrator close to an hour run in under two minutes. The pattern generalises to any task composed of independent, idempotent API calls.
7. Self-Extension
The mechanism that lets the system grow without touching core infrastructure. A specialist whose function is hiring other specialists. When a task requires expertise the roster doesn’t cover, this agent runs a two-phase process: research brief, then approval, then creates the agent file, updates the team profile, and initialises the memory stub.
Most producers skip this component. It’s the one that separates a static setup from a system that learns. A production is not a fixed domain. It changes scope, adds disciplines, hits unexpected technical problems. The Production Context Stack needs to grow with it, and that growth should cost one approval, not an afternoon of configuration work.
Building it
The instinct when reading a seven-component framework is to conclude it needs to be built all at once. It doesn’t.
Start with the Project Constitution. Get the ground rules, naming conventions, and process standards into one version-controlled file. Load it at the start of every session. That single change ends the re-briefing cycle for the most common context, your project’s identity, and starts the habit of treating your AI configuration as a maintained asset.
Add domain rules one context at a time. Start with the context where the agent gets things wrong most often. If it keeps misformatting your tickets, write a ticket rules file. If it consistently misses your spec structure, write a spec conventions file. Each file narrows the gap between what the agent produces and what your production requires.
Build the coordination layer when you add a second specialist. The folder structure takes an afternoon. The hook that injects review alerts takes another hour. Once it exists, the shape of multi-agent work becomes visible in a way it wasn’t before: you can see where work is, what’s queued, and what’s completed.
Persistent memory follows naturally. Once you have specialists and a coordination layer, memory is the next missing piece. It’s also the component with the longest return horizon: the first week, it saves you from re-explaining the same preference twice. After six months, the agent’s accumulated context of your project is a production asset in its own right.
Tool integrations come when you identify the manual task you do most often that an agent could run at scale. For most productions that’s ticket management. Connect your PM tool, write the intent-level instructions, and watch an afternoon of administrative work become a two-minute batch operation. Then find the next one.
Self-extension is the last thing to build, and the most optional. Most productions don’t need it until the roster is already working well. When you reach the point where you’re regularly creating new specialist files, automate the process.
Keeping it alive
The Production Context Stack needs an owner and a review cadence.
Review it every three to six months, and after every major model release. Delete rules written for a previous model’s limitations. A more capable model doesn’t need the guardrails you built because the last one kept making a specific mistake. Dead rules accumulate fast, and they degrade performance: the agent spends attention on constraints that no longer apply.
A standing session review (what worked, what didn’t, what the constitution should say differently) handles continuous maintenance. One owner handles the scheduled reviews. Those two inputs together address the two failure modes: drift from model improvement and drift from project change.
Add a third trigger to the review calendar: policy changes. Your organisation’s AI usage policy will evolve. If you’re delivering work to external clients, their policies may impose additional constraints on which tools you use, which data enters the context, and which integrations are permitted. The Project Constitution is the right place to encode those constraints. Check both sets of requirements when you build, and treat a policy update the same as a model release: a reason to review.
The competitive picture
The GDC 2026 survey found that around 30% of AAA studios now report using proprietary AI systems built on internal data and assets. Two years ago that number was much lower. The studios investing in proprietary infrastructure aren’t doing it because the models got better. They’re doing it because internal AI infrastructure encodes something external tools can’t replicate: your team’s conventions, your project’s domain, your accumulated decisions.
A January 2026 analysis by Aakash Gupta on the agent infrastructure landscape put it plainly: you can’t download this from a package repository. You have to build, test, fail, learn, and rebuild. The Production Context Stack is bespoke by definition. It gets more valuable the longer you maintain it. And it’s not transferable to your competition.
Developers understood this first. The pattern is clear enough now that producers can follow it deliberately, rather than arriving at it by accident after a year of expensive iteration.
The model is commodity. The Production Context Stack is not.
One note: I didn't mention Claude Code by name in this post. That's deliberate. The Production Context Stack is harness-agnostic. The same architecture works with OpenAI Codex, Cursor, Windsurf, Gemini CLI, Copilot Workspace, or any other agent runtime that can read files and call tools. The stack is the advantage, not the choice of harness.